
Architektura RAG: komponenty, które tworzą inteligencję
Poznanie architektury RAG i jej komponentów, to klucz do zrozumienia, jak nowoczesna sztuczna inteligencja tworzy naprawdę użyteczne i wiarygodne odpowiedzi.
W tym artykule odkryjesz, jakie komponenty współpracują ze sobą, aby stworzyć system zdolny do generowania precyzyjnych informacji opartych na aktualnych danych.
To wiedza, która pozwoli Ci lepiej wykorzystać możliwości AI w codziennej pracy i życiu.
Architektura RAG (Retrieval-Augmented Generation) składa się z kilku kluczowych elementów, które razem tworzą potężny system inteligentnego przetwarzania informacji.
Każdy z tych komponentów pełni swoją unikalną rolę, jednak prawdziwa moc RAG tkwi właśnie w ich harmonijnej współpracy.
Zanim zagłębimy się w szczegóły, warto zrozumieć, że każdy element ma swoje miejsce i znaczenie w całym procesie.
Model językowy fundamentem inteligentnych odpowiedzi
W sercu każdej architektury RAG znajduje się model językowy w RAG, który działa jak mózg całego systemu.
Ten zaawansowany algorytm nauczony na ogromnych zbiorach danych tekstowych potrafi generować naturalne, spójne odpowiedzi na podstawie otrzymanych informacji.
Jednak w tradycyjnym podejściu model językowy ma istotne ograniczenie – opiera się wyłącznie na wiedzy, którą zdobył podczas treningu.
Dlatego właśnie integracja z systemem RAG stanowi prawdziwy przełom w funkcjonowaniu modeli językowych.
Zamiast polegać tylko na zapamiętanej wiedzy, model otrzymuje świeże, aktualne informacje z zewnętrznych źródeł.
To oznacza, że może odpowiadać na pytania o wydarzenia z ostatnich dni, analizować najnowsze dokumenty czy korzystać z aktualnych baz danych firmowych.
Model językowy w architekturze RAG pełni funkcję generatora ostatecznych odpowiedzi, ale jego praca opiera się na znacznie szerszym kontekście.
Otrzymuje on nie tylko pierwotne pytanie użytkownika, ale także starannie wyselekcjonowane fragmenty dokumentów i informacji.
Następnie łączy te elementy w spójną, wartościową odpowiedź, która jest zarówno precyzyjna, jak i zrozumiała.
Retriever jako inteligentny wyszukiwacz informacji
Komponent retriever wyszukiwanie informacji w architekturze RAG działa jak niezwykle wyspecjalizowany bibliotekarz, który potrafi błyskawicznie odnaleźć najbardziej istotne informacje.
Jego zadaniem jest przeszukanie dostępnych zasobów i wybranie tych fragmentów, które najlepiej odpowiadają na zadane pytanie.
Proces ten wymaga nie tylko szybkości, ale przede wszystkim precyzji w ocenie relevantności informacji.
Istnieją różne typy retrieverów, każdy z nich dostosowany do specyficznych potrzeb i rodzaju danych.
Retriever wektorowy wykorzystuje matematyczne reprezentacje znaczenia tekstów, dzięki czemu potrafi znajdować informacje semantycznie podobne, nawet gdy nie zawierają dokładnie tych samych słów.
Z kolei retriever tradycyjny opiera się na dopasowaniu słów kluczowych, co sprawdza się doskonale w przypadku wyszukiwania konkretnych terminów czy nazw.
Nowoczesne systemy często wykorzystują hybrydowe podejście retrieverów, które łączy zalety obu metod.
Takie rozwiązanie pozwala na równoczesne wyszukiwanie zarówno na podstawie znaczenia, jak i dokładnych dopasowań słów.
Ponadto zaawansowane retrievery potrafią ocenić kontekst pytania i dostosować strategię wyszukiwania do specyfiki danego zapytania.
Bazy danych jako fundament przechowywania wiedzy
Wybór odpowiedniej bazy danych wektorowe w architekturze RAG ma kluczowe znaczenie dla wydajności i dokładności całego systemu.
Tradycyjne bazy danych relacyjne doskonale sprawdzają się w przechowywaniu strukturalnych informacji, takich jak tabele z danymi liczbowymi, datami czy kategoriami.
Jednak w przypadku pracy z tekstami i semantyką, wektorowe bazy danych oferują znacznie większe możliwości.
Bazy wektorowe przechowują informacje w postaci wielowymiarowych reprezentacji matematycznych, które oddają znaczenie i kontekst tekstów.
Dzięki temu system może błyskawicznie znajdować podobieństwa między zapytaniem użytkownika a dostępnymi dokumentami, nawet gdy używają odmiennego słownictwa.
To właśnie ta technologia umożliwia RAG rozumienie intencji stojącej za pytaniem, a nie tylko dosłownego dopasowania słów.
Jednak najefektywniejsze systemy RAG często wykorzystują kombinację różnych typów baz danych.
Strukturalne dane przechowywane są w tradycyjnych bazach relacyjnych, podczas gdy teksty i dokumenty trafiają do baz wektorowych.
Zatem cały system może korzystać z mocnych stron każdego rozwiązania, zapewniając kompleksowe pokrycie różnorodnych potrzeb informacyjnych.
Embeddingi jako most między słowami a matematyką
Embeddingi technologia semantyczna stanowią prawdziwe serce technologii semantycznej w architekturze RAG, przekształcając ludzki język w matematyczne reprezentacje, które komputer może skutecznie przetwarzać.
Te wielowymiarowe wektory liczbowe oddają nie tylko znaczenie poszczególnych słów, ale także ich wzajemne relacje i kontekst.
Każdy embedding to swoisty „odcisk palca” semantyczny danego fragmentu tekstu.
Proces tworzenia embeddingów opiera się na zaawansowanych algorytmach uczenia maszynowego, które analizują ogromne ilości tekstów, aby zrozumieć, jak słowa i frazy funkcjonują w różnych kontekstach.
W rezultacie słowa o podobnym znaczeniu otrzymują podobne reprezentacje wektorowe, co pozwala systemowi rozpoznawać synonimy, analogie i powiązania semantyczne.
Ponadto embeddingi potrafią uchwycić subtelne różnice w znaczeniu tego samego słowa używanego w różnych kontekstach.
W praktyce embeddingi umożliwiają inteligentne wyszukiwanie, które wykracza daleko poza proste dopasowywanie słów kluczowych.
Gdy użytkownik pyta o „sposób zwiększenia produktywności”, system potrafi znaleźć dokumenty mówiące o „poprawie wydajności” czy „optymalizacji pracy”, ponieważ embeddingi tych fraz są matematycznie podobne.
To właśnie dzięki tej technologii RAG może oferować naprawdę inteligentne i kontekstowe odpowiedzi.
Symfonia współpracy między komponentami
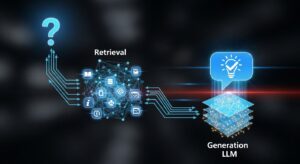
Prawdziwa moc architektury RAG ujawnia się dopiero wtedy, gdy wszystkie komponenty współpracują ze sobą w harmonijny sposób.
Proces rozpoczyna się od otrzymania pytania użytkownika, które następnie jest przekształcane w embedding wektorowy. Ten matematyczny opis zapytania staje się kluczem do przeszukania bazy danych w poszukiwaniu najbardziej relevantnych informacji.
Retriever wykorzystuje otrzymany embedding do przeprowadzenia inteligentnego wyszukiwania w bazie wiedzy, porównując podobieństwo wektorowe zapytania z dostępnymi dokumentami.
Następnie wybiera te fragmenty, które wykazują największe podobieństwo semantyczne do zadanego pytania.
Ten proces odbywa się błyskawicznie, nawet przy przeszukiwaniu ogromnych zbiorów danych zawierających miliony dokumentów.
Wybrane przez retriever informacje trafiają następnie do modelu językowego wraz z pierwotnym pytaniem.
To tutaj następuje ostatni, kluczowy etap procesu – model analizuje dostarczone konteksty i generuje ostateczną odpowiedź, która łączy informacje z różnych źródeł w spójną całość.
Zatem użytkownik otrzymuje nie tylko dokładną informację, ale także naturalnie brzmiącą odpowiedź, która bezpośrednio odnosi się do jego zapytania.
Cały ten proces odbywa się w czasie rzeczywistym, jednak jego jakość zależy od precyzyjnego dostrojenia wszystkich komponentów.
Każdy element musi być odpowiednio skonfigurowany i zoptymalizowany, aby całość działała płynnie i dostarczała wartościowe rezultaty.
Dlatego implementacja RAG wymaga nie tylko technicznych umiejętności, ale także głębokiego zrozumienia specyfiki danej domeny i potrzeb użytkowników.
Zrozumienie architektury RAG otwiera przed nami fascynujący świat możliwości wykorzystania sztucznej inteligencji w praktycznych zastosowaniach.
Do tej pory opublikowane artykuły z cyklu „RAG w AI: jak działa i dlaczego zmienia wszystko” to kompleksowe źródło wiedzy na temat tej rewolucyjnej technologii.
Poprzednie części cyklu: RAG krok po kroku: od pytania do odpowiedzi w AI
oraz RAG w AI: Rewolucja w Wiarygodności Sztucznej Inteligencji,
stanowią doskonałe uzupełnienie dzisiejszych rozważań o komponentach tworzących tę zaawansowaną architekturę.
Zachęcam wszystkich czytelników do pozostawienia komentarzy, dzielenia się swoimi doświadczeniami oraz przemyśleniami na temat przedstawiony powyżej.
Wasze opinie są dla mnie niezwykle cenne!
Jeśli uznacie, że moje rozważania są wartościowe, weźcie pod uwagę również wsparcie naszej telewizji poprzez wpłatę darowizny: https://zrzutka.pl/frujg8
Dzięki temu będziemy mogli kontynuować nasze działania i dzielić się wiedzą przygotowując jeszcze bardziej praktyczne wskazówki i programy.
Wasze wpłaty w całości zostaną przeznaczone na opłaty licencji oprogramowania, obsługę hostingu, serwera i strony internetowej.
Te koszty są dość znaczne.
Bez Waszej pomocy zmuszeni będziemy zakończyć bezpłatne dzielenie się wiedzą.
Nota redakcyjna:
Artykuł ten został opracowany na podstawie ogólnych trendów i dyskusji dostępnych publicznie.
Treści mają charakter informacyjny i edukacyjny, nie stanowią profesjonalnej porady.
Redakcja zaleca konsultację z wykwalifikowanymi specjalistami w przypadku osobistych doświadczeń.
Opinie wyrażone w tekście są subiektywne i mogą nie odzwierciedlać stanowiska wszystkich czytelników.
Materiał nie promuje żadnej konkretnej ideologii, a wszelkie przykłady służą ilustracji uniwersalnych tematów.
Nota prawna:
Wszelkie prawa autorskie do niniejszego tekstu, w tym treści, struktury i elementów oryginalnych, należą wyłącznie do autora.
Kopiowanie, reprodukcja, modyfikacja, rozpowszechnianie lub jakiekolwiek inne wykorzystanie materiału
w celach zarobkowych bez uprzedniej pisemnej zgody autora jest surowo zabronione i stanowi naruszenie prawa autorskiego zgodnie z ustawą o prawie autorskim i prawach pokrewnych (Dz.U. 1994 nr 24 poz. 83 z późn. zm.) oraz innymi obowiązującymi przepisami prawa międzynarodowego.
Copyright © 2026 Marek Zadęcki.











Jeden komentarz